贵如黄金的内存该怎么选?32/48/128GB内存游戏生产力性能实测!
随着DDR5技术的日益成熟以及颗粒良品率的提升,曾经被视为“高不可攀”的高频DDR5内存如今已飞入寻常百姓家。与此同时,软件环境的变化——从3A游戏对显存和内存吞吐的渴望,到AIGC、视频剪辑等生产力工具对大容量内存的硬性需求——都在迫使玩家重新审视自己的内存配置。在平台上,DDR5-8000+似乎已成为发烧友的标配,但在采用Chiplet小芯片设计的 AM5平台上,情况则显得更为复杂且微妙。

积热问题、FCLK的体质墙、以及分频机制(1:1 vs 1:2)的博弈,使得AMD平台的内存调教成为了一门“玄学”。为了在这个内存贵如黄金的时代,帮助各位主流玩家选择合适的内存,我们本次也是斥巨资组建了三套极具代表性的内存方案,涵盖了32GB主流电竞标配、48GB新晋甜点,以及128GB顶格工作站级容量。在游戏、生产力以及理论性能等方面进行实测,试图为你揭开AMD平台内存性能的终极面纱。
测试平台介绍
为了最大限度地消除系统瓶颈并放大内存性能的差异,我们选用了目前的AMD消费级旗舰平台进行测试。处理器方面,采用了AMD Ryzen 9 9950X以模拟高端用户的实际使用环境;

主板则选用了微星MSI MPG X870E CARBON WIFI 暗黑主板,这款主板优秀的走线优化是支持高频内存的坚实基础。



完整测试平台如下所示:

参测内存选手介绍
本次测试的三组内存极具看点,分别代表了三种截然不同的用户画像。首先是代表“电竞标准”的32GB(2x16GB)组,我们采用了SK Hynix A-Die颗粒,分别测试了AMD官方认证的“甜点”频率DDR5-6000 CL30,以保证1:1同频模式的低延迟优势,以及挑战IMC极限的DDR5-8000 CL36,这需要开启1:2分频模式。


其次是“进阶全能”的48GB(2x24GB)组,该组采用新款24Gbit M-Die颗粒,其特点是在不牺牲频率的前提下比传统内存提升了50%的容量,且得益于新工艺,其超频潜力往往优于老款M-die,甚至在某些时序上能追平A-die。


最后是“生产力巨兽”128GB(2x64GB)组,这是本次测试的难点,受限于AM5平台的物理电气性能,其运行频率被限制在DDR5-6000 CL34,这也代表了目前AMD平台在容量与速度平衡上的极限。


理论性能测试
首先我们对三款内存的读写带宽以及延迟进行了详细测试,不得不说,测试结果还挺有趣,完全打破了“频率越高带宽越强”的传统认知。
测试数据显示,32GB A-die内存从6000MHz提升至8000MHz后,读取带宽竟然几乎没有提升(从86.6 GB/s微增至87.1 GB/s)。这意味着在32GB容量下,单纯拉高频率遭遇了严重的边际效应递减。虽然写入速度提升到了95 GB/s,但延迟却从71.9ns恶化到了75.6ns。花费巨大精力上8000MHz,却换来了几乎相同的读取带宽和更高的延迟。

相比之下,48GB M-die展现了惊人的扩展性。在8000MHz下,它跑出了93.2 GB/s的读取和突破天际的100.2 GB/s写入带宽,显著超越了32GB组。更令人震惊的是延迟表现:48GB组在8000 C36下的延迟仅为69.8ns,甚至比它自己在6000 C30下的70.7ns还要低(也低于32GB组)。这证明了新一代24Gbit颗粒在高频下的电气性能极为优异,能更好地消化高频带来的红利。

至于128GB的超大容量组合,在6000MHz C34下,其读取带宽为73.5 GB/s,写入为79 GB/s,相比起上面的两组来说,还是有些差距的。不过对于需要海量吞吐的渲染任务来说,128GB的超大容量还是有它的用武之地的。

紧接着我们还进行了7-Zip的相关测试,7-Zip基准测试是对内存带宽和延迟最为敏感的测试之一,尤其是“压缩”过程,它能最直观地反映内存吞吐能力对工作效率的影响。
测试数据显示,48GB DDR5-8000 C38在压缩性能上展现了统治级的表现,得分高达 246 GIPS,相比同容量的6000组(213 GIPS)提升了约15%,同时也显著高于32GB 8000组(233 GIPS)。这证明了新一代24Gbit M-die颗粒在高吞吐场景下的实力,它是处理大量数据包时的最佳选择。

而128GB内存受限于6000MHz频率和相对宽松的时序,在压缩测试中垫底(189 GIPS),如果你处理的是数据搬运密集型的任务,那目前来看,频率依然是硬道理。
下面进行的则是GeekBench6理论性能测试,它模拟了更广泛的应用场景,从图像处理到机器学习,能反映内存对综合算力的辅助作用。
实测在单核性能上,无论频率是6000还是8000,容量是32G还是128G,单核得分均稳定在 3400-3470 之间。这说明对于绝大多数日常轻负载应用(如网页浏览、文档编辑),内存规格的差异几乎不可感知,不会成为系统瓶颈。
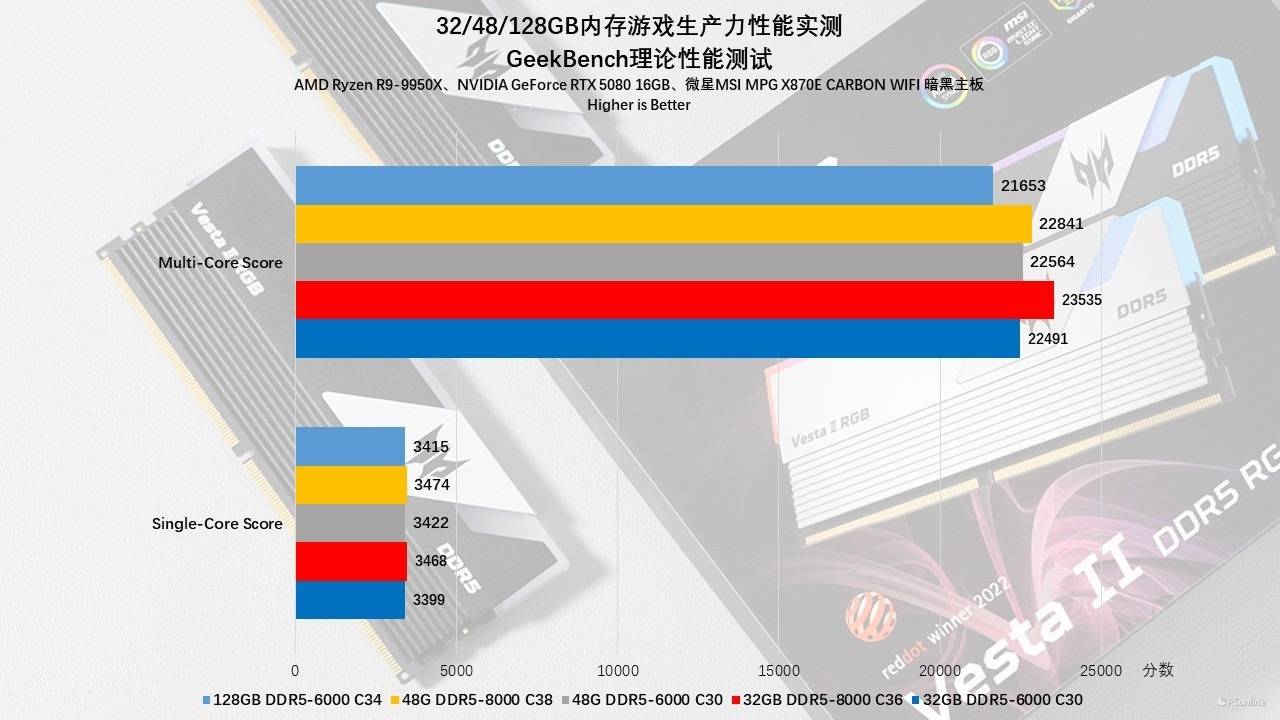
多核的情况则略有不同,尽管48GB组在AIDA64的理论带宽和延迟中占优,但在GeekBench 6多核测试中,32GB DDR5-8000 却以 23535分 实现了反超。这就不得不提到内存子时序的问题了,目前的AM5主板BIOS对于成熟的16Gbit A-die颗粒(32GB)调教更为透彻,往往能自动给出一套更紧致的副时序;而24Gbit M-die(48GB)作为新颗粒,为了兼容性,主板自动给的副时序往往偏宽一些。
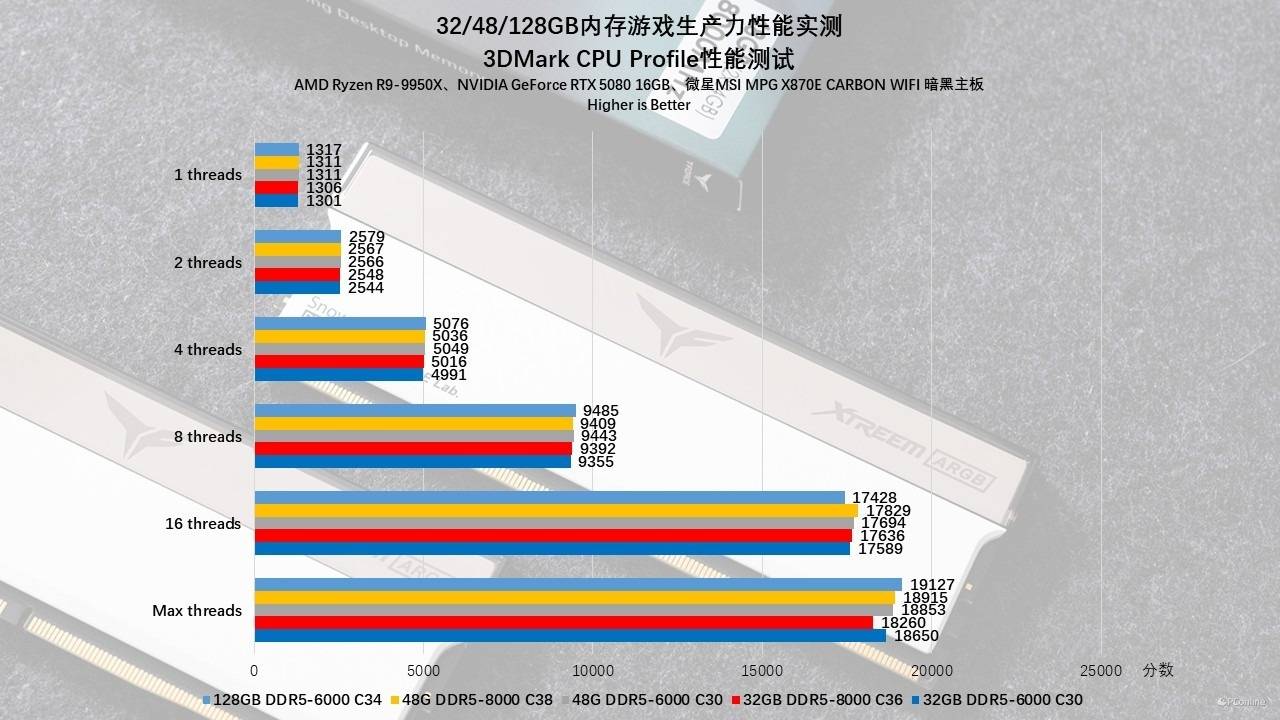
理论性能的最后我们进一步测试了3DMark,在Time Spy与Fire Strike测试中,有一个有意思的现象,那就是时序效率优于单纯的高频带宽:以48GB组为例,在Time Spy测试中,运行在1:1模式且时序更紧的DDR5-6000 C30(16325分)竟然反超了DDR5-8000 C38(15937分)。这有力地证明了在游戏物理模拟这类对延迟敏感的场景下,盲目追求8000MHz而不得不放宽时序(C38)或使用1:2分频,反而会导致性能倒退。而同频下大容量则存在一定优势:对比同为6000 C30的设置,48GB组得分普遍略高于32GB组。如果128GB内存的时序能够再紧一些,分数应该不会比另外两组低。

而在CPU Profile测试中,似乎呈现了“容量制胜”定律,得分随容量阶梯式上涨。在Max Threads这种榨干CPU算力的场景下,128GB (19127分) > 48GB (18915分) > 32GB (18650分),这也进一步说明,在涉及全核心满载的复杂物理模拟或多线程计算任务中,增加内存容量能显著减少数据交换的等待时间,其带来的性能收益远超单纯拉高频率。
创作性能测试
创作领域的测试结果也非常有意思,在基于PugetBench和UL Procyon的创意软件测试中,内存表现呈现出一种“精神分裂”的状态,这也打破了“频率越高越好”的单一神话。
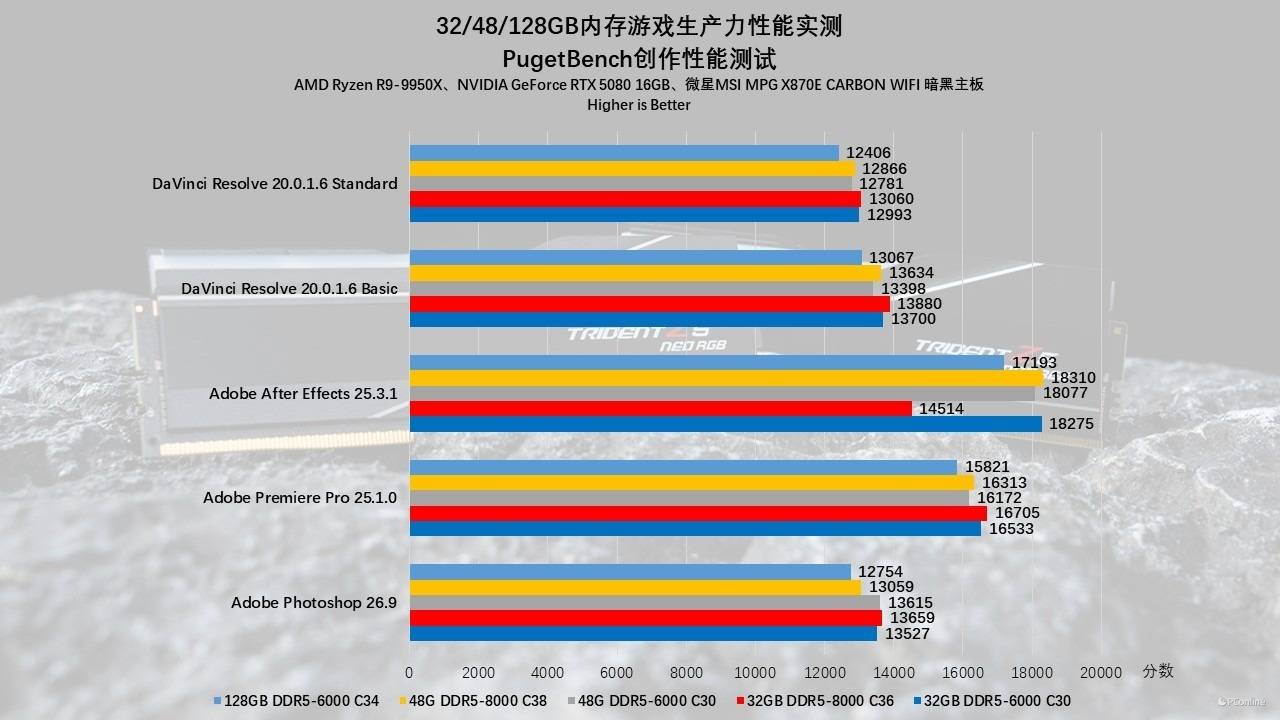
对于依赖线性数据流处理的任务,如Premiere Pro的视频导出、Photoshop的滤镜批处理以及Lightroom的照片转码,高频优势明显,32GB DDR5-8000 C36凭借高带宽拿下了各项测试的榜首,特别是在UL Procyon的视频编辑导出分中,它比128GB组快了约3%。

然而,在After Effects这类涉及大量图层合成、内存预览缓存的复杂场景中,剧情发生了惊天反转:48GB DDR5-6000 C30以18310的高分傲视群雄,而32GB 8000组却跌至14514分。这充分说明,对于复杂的合成类工作流,1:1同频模式下的极低延迟(C30时序)配合48GB的中等容量,其收益远高于单纯拉高频率却牺牲时序的8000MHz方案。至于128GB组,虽然受限于C34时序导致跑分略低,但它是唯一能保证在8K项目或超长特效合成中不爆显存、不崩溃的“安全底线”。
在3D渲染(Blender、V-Ray)与视频编码(X264/X265)的对比测试中,也有这种情况出现。例如视频编码本质上是一个极度吞噬带宽的过程,测试数据显示,无论是X264还是X265编码,DDR5-8000组都稳稳压制了6000组,提升幅度在4%-8%之间,这是高频内存最高光的时刻。
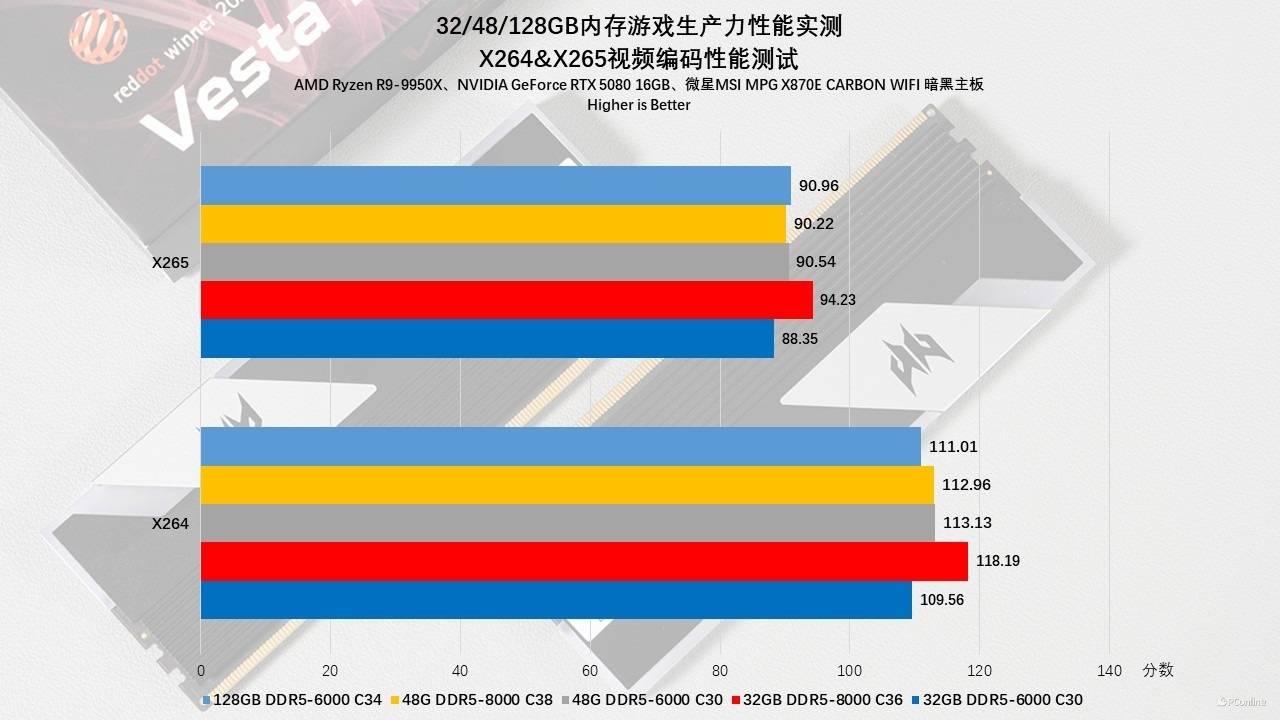
然而,一旦转入Blender和V-Ray这类纯粹的光线追踪渲染任务,情况则截然相反:32GB DDR5-6000 C30(1:1模式)的渲染速度竟然反超了32GB DDR5-8000 C36。说人话就是CPU核心在等待光线反射数据时,对内存的响应延迟更为敏感。因此,对于构建渲染农场的用户来说,与其花大价钱追求不稳定的8000MHz,不如踏实选择一套时序紧致的6000MHz C30内存,这不仅更稳,跑得反而更快。


游戏性能测试
对于游戏玩家而言,最关心的问题莫过于高频与大容量的实际收益,而测试结果可能会让盲目追求高频的玩家失望。
首先是3A大作方面的测试,第一个请出的是国产3A之光《黑神话:悟空》。在1080p极高画质下,这款虚幻5引擎的大作展现出了典型的“众生平等”特性。测试数据显示,五组内存的平均帧数惊人地一致,稳定在72-73 FPS之间,说明即便在低分辨率下,GPU依然是主要瓶颈。然而在关乎流畅度的1% Low帧(最低帧)上,32GB DDR5-8000 C36 还是凭借极致的带宽优势,以61 FPS的成绩略微领先于48GB 6000组的59 FPS。这说明在极度压榨显卡的场景中,极高频内存对缓解偶尔的数据吞吐拥堵有一丝微弱的帮助,但并未拉开质的差距。

来到1440p(2K)分辨率,显卡瓶颈进一步收紧,内存性能的差异几乎被完全抹平。无论是售价昂贵的8000MHz高频条,还是插满128GB工作站配置,平均帧数均锁定在57 FPS,1% Low帧也稳定在48 FPS左右。

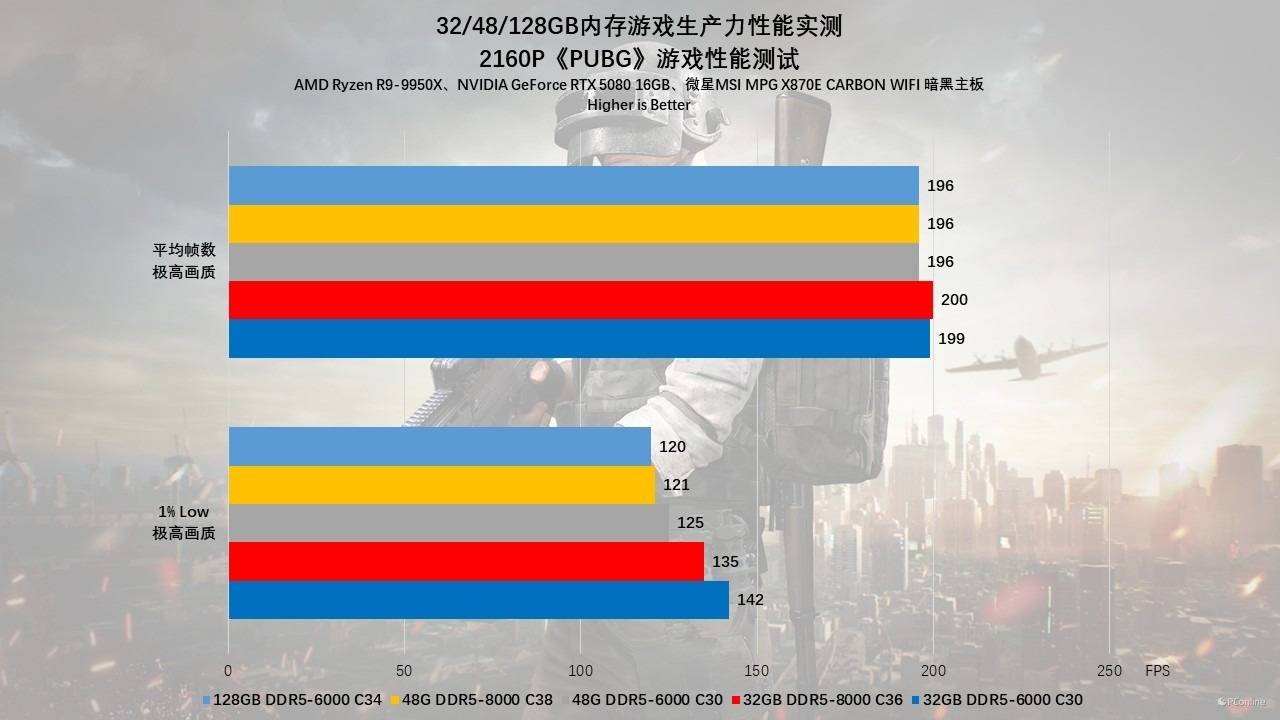
到了2160p(4K)画质,系统负载完全转移至GPU端。有趣的是,即便在这种极限画质下,128GB组的表现依然坚挺,与32GB高频组毫无二致。
第二款游戏我们测试的是《赛博朋克2077》,在1080p分辨率下,夜之城的复杂车流与NPC逻辑运算让这里成为了检验内存效能的修罗场。32GB DDR5-8000 C36 在此展现了统治力,以208 FPS的平均帧和154 FPS的1% Low帧傲视群雄。然而,48GB DDR5-8000 C38 却遭遇了滑铁卢,其平均帧(195 FPS)和1% Low帧(141 FPS)竟然大幅落后于同容量的48GB DDR5-6000 C30(平均205 FPS / Low 150 FPS)。

当分辨率提升至1440p,CPU负载压力减轻,内存排位发生了微妙的变化。48GB DDR5-6000 C30 凭借1:1模式的低延迟优势,在1% Low帧表现上以128 FPS反超了所有对手,甚至高于32GB 8000组的124 FPS。这进一步印证了在中等负载下,Ryzen 7000/9000平台对时序、延迟的敏感度远高于带宽。至于128GB,虽然平均帧能咬住大部队,但在1% Low帧上还是显露疲态,仅为125 FPS,不过对于非电竞玩家来说,128GB显然是为工作准备的,这完全在可接受范围内。

在2160p光追开启的极限环境下,显卡再次成为绝对瓶颈,所有内存组的平均帧都被压缩到了73-74 FPS的区间内。此时,内存规格的差异已属于误差范围。不过128GB还是有优势的,这对于那些喜欢一边开着几十个Chrome标签页查攻略、一边运行4K光追游戏的重度用户来说,128GB提供的“情绪价值”和稳定性远比那1-2帧的波动来得重要。

下面则是电竞网游专场,首先出场的是大家耳熟能详的《CSGO 2》,在1080p下,CS 2对延迟的敏感度达到了毫秒级,这是32GB DDR5-8000 C36 的绝对主场。它不仅跑出了474 FPS的超高平均帧,更重要的是在决定生死瞬间的1% Low帧上,达到了惊人的 216.5 FPS,大幅领先其他所有组别。相比之下,48GB 8000组受累于1:2分频,1% Low帧暴跌至195 FPS,总的来说,极致时序配合高频依然是FPS电竞的唯一真神。

1440P下其实可以算得上是众生平等,其中表现更为出色的则是48GB DDR5-6000 C30在平均帧(371 FPS)和1% Low帧(199.5 FPS)上均实现了反超。不过这对于本身已经几百帧的游戏来说,这一点点帧数差距,其实很难感知得到。
在2160p分辨率下,CS 2的帧数依然保持在200 FPS以上,但出现了一个极其反直觉的现象:128GB组 在1% Low帧上竟然以115.4 FPS位列第一,反杀了所有高频内存。这可能归功于4K分辨率下纹理数据量激增,而128GB的大容量能够最大化地减少了CPU等待数据的时间。

第二款网游我们测试的则是《永劫无间》,测试数据显示,在1080p极高画质下,48GB DDR5-6000 C30 凭借1:1模式的低延迟优势,1% Low帧达到了111 FPS,而32GB DDR5-8000 C36 竟然暴跌至79 FPS,跌幅接近30%。这种因1:2分频导致的剧烈卡顿在拼刀博弈中是致命的。

即使在1440P分辨率下,也是这种情况,五组数据的平均帧其实都差不多,但是高频组的1%Low都比6000MHz加低时序的要少一些。这再次印证了Unity引擎在常规电竞分辨率下,对紧致时序的偏爱远胜于高频。

当来到2160p(4K)分辨率时,虽然平均帧数大家都能维持在41 FPS左右(显卡瓶颈),但在1% Low帧上,各组的差异还是比较明显的,其中6000MHz搭配低时序明显要优于高频但相对宽松的时序。因此,对于《永劫无间》玩家,48GB/32GB DDR5-6000 C30 是兼顾流畅与稳定的唯一解。

至于另外一款基于UE5打造的网游《漫威争锋》的情况也是比较类似的,在1080P下,同样是甜点频率加低时序为王。而128GB的内存在这里则因为时序较为宽松,因此成绩稍稍落后一些。

2K分辨率下,8000MHz的成绩对比6000MHz下也是出现了倒挂,其中32GB DDR5-6000 C30 继续领跑,1% Low帧守住了 101 FPS 的大关,是全场唯一破百的成绩。而DDR5-8000组别虽然理论带宽巨大,但在实际游戏中的1% Low帧跌至97 FPS。至于128GB组,受限于C34的时序,1% Low帧滑落至85 FPS,成为了垫底的存在。

即便在2160p(4K)分辨率下,显卡成为最大瓶颈时,内存性能的微弱差异依然被放大。32GB DDR5-6000 C30 依然凭借 62 FPS 的1% Low帧傲视群雄,显著高于其他所有组别(54-57 FPS)。

最后一款游戏我们测试的则是《绝地求生》,在1080p分辨率下的测试结果延续了“甜点频率+低时序”的传统定律。其中32GB DDR5-6000 C30的1% Low帧高达 224 FPS,以碾压之势击败了48GB组(156 FPS)和128GB组(142 FPS)。即使是DDR5-8000高频条,在1080p下也只能跑到199 FPS。这证明了在低分辨率下,PUBG对内存时序会更为敏感。

2K和4K分辨率下其实情况也差不多,各组的平均帧其实都差不多,但是1%Low倒是有比较大的区别,其中更好的自然是6000MHz加低时序的一组,不过32GB和48GB亦有区别,究其原因还是我们之前讲的,A-die颗粒可能更为成熟一些,因此时序可以压得更紧,从而表现会更好。

评测总结
经过漫长的测试与数据分析,我们得出的结论十分清晰。在AMD平台上,从DDR5-6000提升至DDR5-8000,虽然理论带宽提升巨大,但受限于1:2分频机制,实际游戏性能提升微乎其微,在《绝地求生》等游戏中甚至会出现1% Low帧数下降的“负优化”。考虑到为了稳住8000MHz所付出的昂贵主板成本、散热成本和极高的折腾精力,其性价比极低。相反,从32GB升级到48GB几乎没有副作用,频率不降、延迟不变,却带来了50%的容量余量,极大缓解了多任务焦虑。而128GB则是纯粹的生产力工具,它牺牲了部分延迟和频率,换取了无可替代的稳定性与工作流吞吐量。

对于纯粹的FPS或MOBA电竞玩家,32GB (2x16GB) DDR5-6000 C30是目前性价比最高的选择,足以应付主流网游且即插即用。对于高端玩家、3A大作爱好者及轻度创作者,48GB (2x24GB) DDR5-6000 C30或6400是目前的“黄金方案”,兼顾了大容量与优秀颗粒体质。至于专业内容创作者,建议优先考虑96GB或128GB的方案。