ICCV 2025 | ETH Zurich&Meta提出PHD:扩散模型先验,实现高精度个性化3D人体拟合
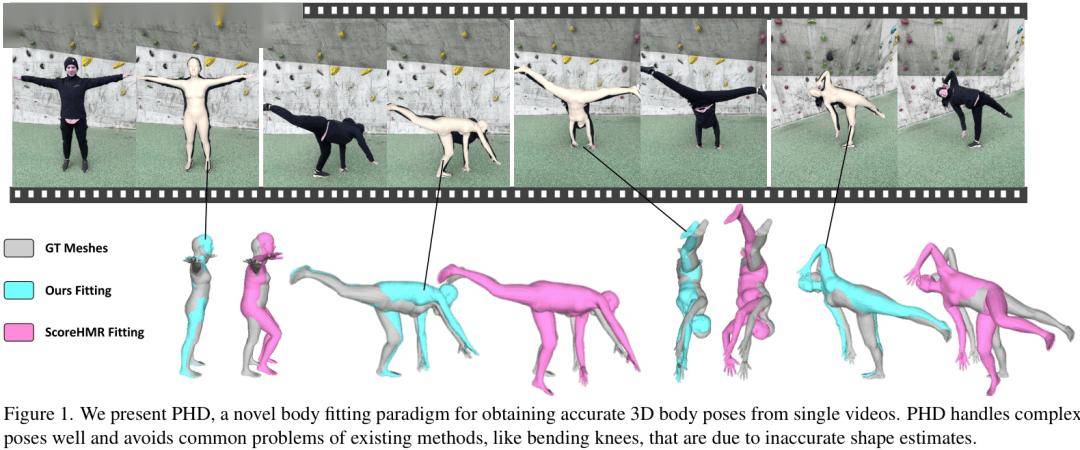
从单张图片或视频中恢复人体的三维姿态和体型(Human Mesh Recovery, HMR)是实现虚拟化身、人机交互和行为分析的关键技术。然而,现有方法大多是“一视同仁”的通用模型,它们在拟合时常常忽略个体间的身材差异,导致为了对齐二维图像而产生“膝盖异常弯曲”等不符合三维物理现实的怪异姿态。
为了解决这一难题,来自 苏黎世联邦理工学院(ETH Zürich)和 Meta的研究者们提出了一种名为 PHD (Personalized 3D Human Body Fitting)的新方法。其核心思想非常直观:先认识你,再为你量身打造。PHD通过一个创新的两阶段流程,首先从视频中标定出特定用户的准确身体形状,然后利用这个“专属”形状信息作为先验知识,指导后续的3D姿态拟合。为此,他们开发了一个基于点扩散模型的强大3D姿态先验,能够显著提升姿态估计的准确性,尤其是以往工作常常忽略的绝对姿态精度。

论文标题:PHD: Personalized 3D Human Body Fitting with Point Diffusion
作者:Hsuan-I Ho, Chen Guo, Po-Chen Wu, Ivan Shugurov, Chengcheng Tang, Abhay Mittal, Sizhe An, Manuel Kaufmann, Linguang Zhang
机构:苏黎世联邦理工学院 (ETH Zürich)、Meta Reality Labs
论文地址:https://arxiv.org/abs/2508.21257
项目地址:https://phd-pose.github.io/
会议信息:ICCV 2025
研究背景与动机
传统的HMR方法通常采用“一步到位”的策略,即同时从图像中回归或优化求解人体的形状(shape)、姿态(pose)和位置。这种方式虽然通用,但存在固有缺陷:
形状估计不准且不稳定:由于衣物遮挡和视角限制,从单帧图像很难精确估计体型。在视频序列中,估计出的体型参数常常会随时间抖动,这显然不符合物理事实。
过度依赖2D约束:为了让3D模型在图像上看起来“对齐”,优化过程会过度拟合2D关键点。如果体型估算错误(比如腿比实际短),模型为了匹配2D投影,就会强行“掰弯”膝盖,牺牲了3D姿态的真实性。
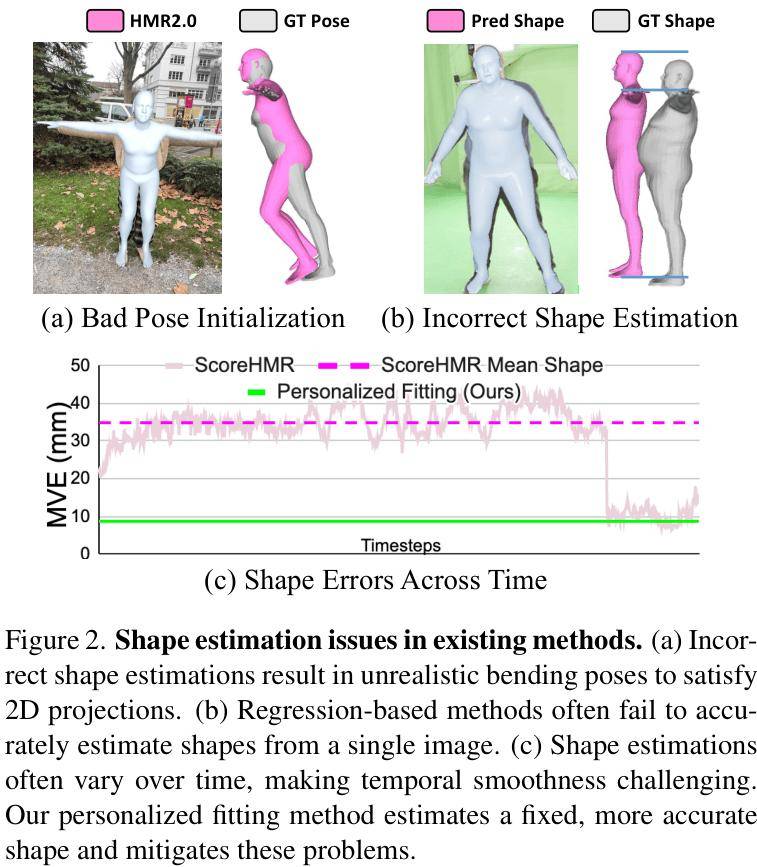
上图直观展示了现有方法中因形状估计不准(a, b)和随时间变化(c)导致的问题。PHD的目标就是通过个性化流程来解决这些痛点。
PHD:个性化两步走流水线
PHD将复杂的HMR问题解耦为一个清晰的两阶段流水线:个性化标定和 个性化拟合。
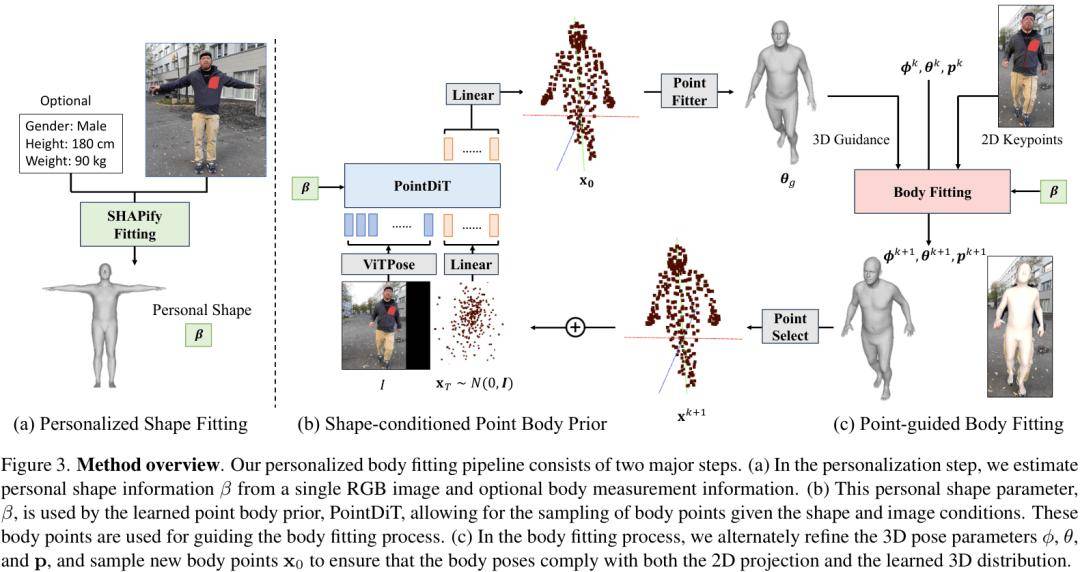
阶段一:个性化形状标定 (SHAPify)
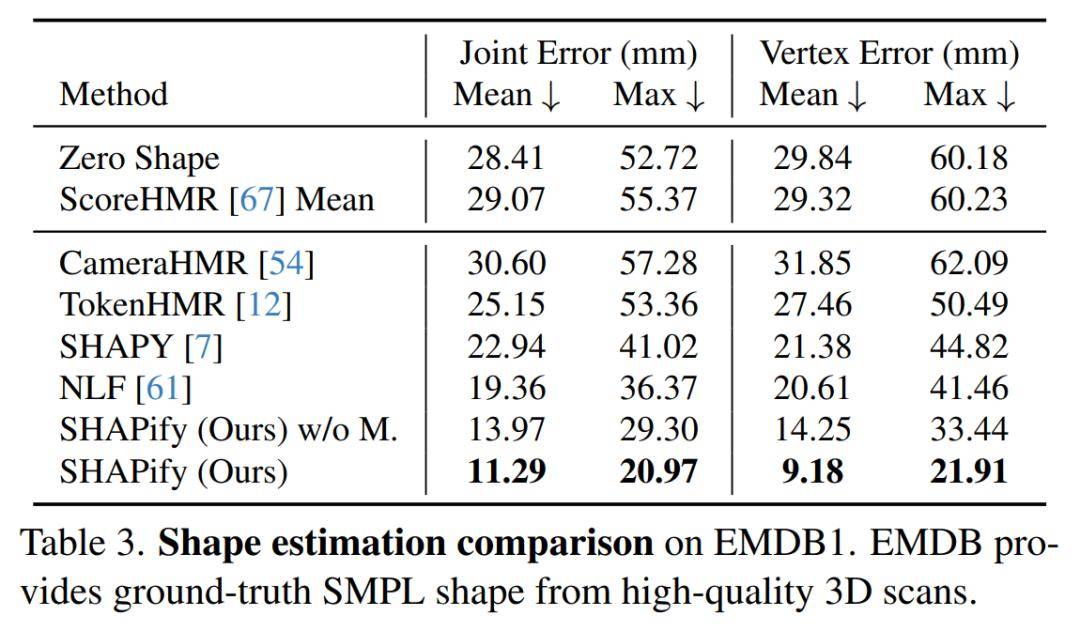
在处理一段视频前,PHD首先需要“认识”视频中的主角。用户只需提供一张处于放松姿态(如T-pose或I-pose)的校准图像,PHD就能通过一个名为 SHAPify的优化模块,估算出稳定且精确的身体形状参数β。如果能额外提供身高、体重等信息,标定结果会更准确。这一步对于每个用户只需进行一次。
阶段二:基于形状先验的个性化姿态拟合
在获得用户的专属形状β后,就进入了逐帧的姿态拟合阶段。这是PHD的核心创新所在。研究者没有直接优化姿态参数,而是引入了一个强大的 形状条件下的3D姿态先验,该先验被实现为一个名为 Point Diffusion Transformer (PointDiT)的模型。
PointDiT不再像传统方法那样学习关节旋转角度的分布,而是直接学习在给定用户体型β和图像特征的条件下,生成符合人体结构的三维身体点云。相比于抽象的旋转角度,点云能更直观、更紧密地与体型和图像信息相关联。
在拟合过程中,PHD采用了一个迭代优化的循环:
使用PointDiT根据当前姿态和用户体型,生成一个“合理”的3D身体点云作为目标。
通过一个新颖的 点蒸馏采样损失 (Point Distillation Sampling loss),引导当前的姿态参数向这个“合理”的目标点云和2D图像约束共同决定的方向进行优化。
交替进行点云采样和姿态优化,确保最终结果既符合3D人体先验,又与2D图像对齐。
这种机制极大地缓解了对2D约束的过度依赖,能有效修正不合理的初始姿态,得到更鲁棒和精确的结果。
实验结果与分析
PHD在多个基准数据集上进行了验证,并取得了SOTA性能。
更高的绝对姿态精度
传统方法通常只评估骨盆对齐后的局部姿态精度(MPJPE-PA),但这忽略了人体在相机空间中的绝对位置和朝向。PHD不仅在局部精度上表现出色,更在 绝对姿态精度(C-MPJPE)这一更具挑战性、也更实用的指标上取得了显著提升。这证明了准确的体型先验对于恢复人体的真实空间状态至关重要。

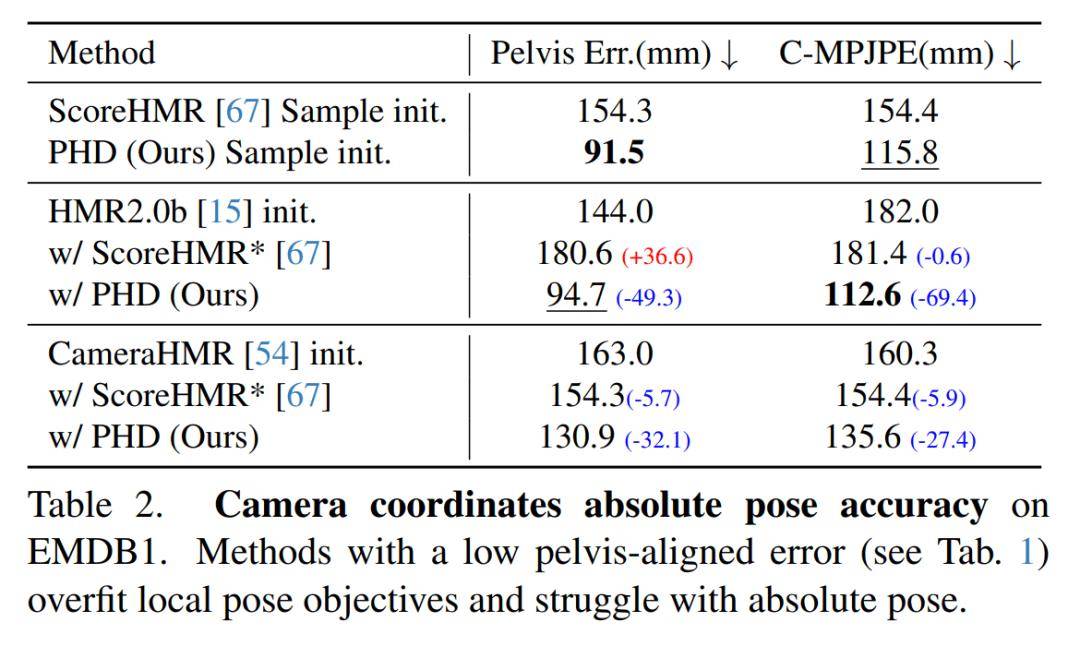
强大的坏姿态修正能力
定性比较显示,即使初始姿态非常糟糕(如来自HMR2.0b的错误预测),PHD强大的点扩散先验也能将其“拉回”到正确的状态,而基线方法ScoreHMR则难以恢复。这体现了PHD作为优化模块的鲁棒性。

数据高效与即插即用
值得一提的是,PHD的训练 仅需合成数据(BEDLAM),无需任何真实世界的3D标注,大大降低了训练成本。同时,它可以作为一个通用的 即插即用(plug-and-play)模块,无缝集成到现有的3D姿态估计器(如CameraHMR)之后,进一步提升它们的性能。
论文贡献与价值
PHD的提出为3D人体网格恢复领域带来了新的思考范式,其主要贡献如下:
提出个性化HMR新范式:将HMR解耦为“形状标定”和“姿态拟合”两个阶段,有效利用用户身份信息来提升精度和鲁棒性。
创新的点扩散姿态先验:开发了PointDiT,一个基于点扩散的强大3D姿态先验模型,它以点云为媒介,比传统的基于关节角度的先验更有效、更直观。
关注并提升绝对姿态精度:强调了绝对姿态精度在实际应用中的重要性,并通过个性化方法在该指标上取得了显著进步。
实用性强:模型训练数据高效,且能作为插件模块提升现有SOTA方法的性能,具有很高的应用价值。
PHD的思路清晰且有效,它抓住了传统HMR方法中“形状”与“姿态”纠缠不清的核心痛点,并给出了一个优雅的解耦方案。这种“先个性化,再拟合”的思想,对于未来构建更真实的个人数字分身、实现更精准的人体行为理解等应用,无疑铺平了道路。
从单张图片或视频中恢复人体的三维姿态和体型(Human Mesh Recovery, HMR)是实现虚拟化身、