雷军官宣小米多篇最新研究成果成功入选ICLR 2026国际顶级会议
IT之家 2 月 3 日消息,小米创办人、董事长兼 CEO 雷军今日宣布,小米团队的多篇最新研究成果,成功入选 ICLR 2026,研究方向涵盖多模态推理、强化学习、GUI Agent、端到端自动驾驶以及音频生成等领域。
IT之家注:ICLR(国际学习表征会议,全称是 International Conference on Learning Representations)是人工智能领域国际顶级会议之一,由图灵奖得主 Yoshua Bengio 和 Yann LeCun 于 2013 年创立的深度学习领域学术会议,致力推动人工智能理论与方法的前沿研究与创新发展。
小米本次入选国际顶级会议 ICLR 2026 的研究成果如下:
《Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle》
《MobileIPL: Enhancing Mobile Agents Thinking Process via Iterative Preference Learning》
- 论文作者:朱泠皞,管一然,梁定康,鞠建忠,罗振波,秦斌,栾剑,刘禹良,白翔
- 论文链接:https://arxiv.org/abs/2508.05612
- 项目链接:https://github.com/xiaomi-research/shuffle-r1
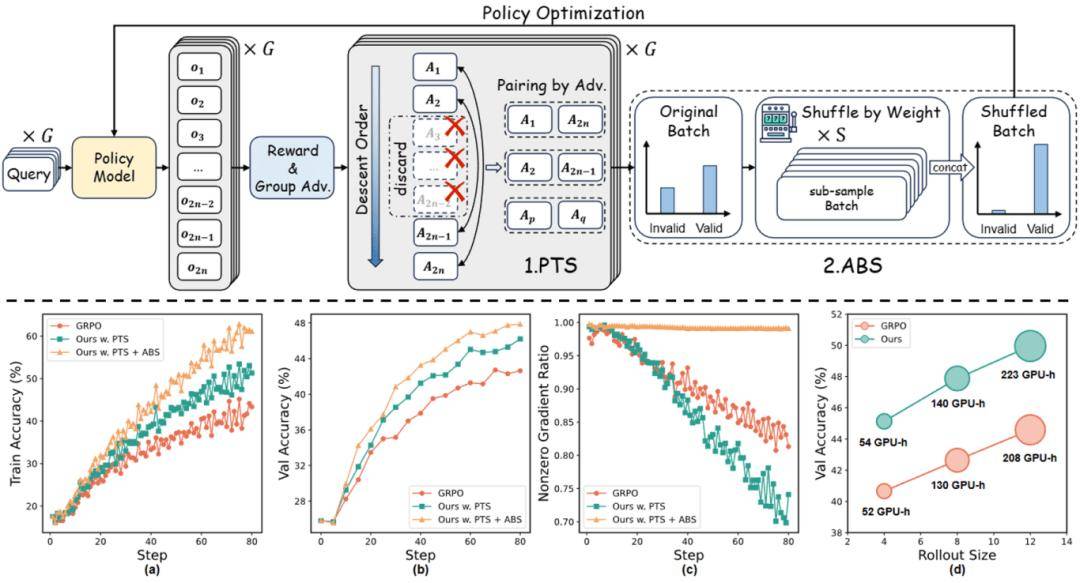
强化学习已成为提升多模态语言模型推理能力的重要后训练范式。然而,现有的强化学习训练流程在训练中仍面临效率低下的问题,其根源在于两个长期被忽视的关键现象:优势坍缩(Advantage Collapsing)。即一个批次中的大多数优势值集中在零附近,导致导致有效梯度信号不足;以及轨迹沉默(Rollout Silencing),即能够产生非零梯度的采样轨迹数量随着训练进行不断减少,进一步削弱了学习效率。这些问题使得模型的梯度更新受限,严重制约了模型的长期优化能力。
针对上述挑战,本文提出了 Shuffle-R1,这是一个简洁高效的强化学习框架,通过数据层面的动态重组显著提升强化学习的训练效率。Shuffle-R1 包含两项核心设计:(1)成对轨迹采样(Pairwise Trajectory Sampling),该方法选择具有大优势值的高对比度轨迹,以提高梯度信号质量;(2)基于优势的批次重排序(Advantage-based Batch Shuffle),通过精心设计的批次重排序算法重塑了训练批次的数据分布,以此来增加更有价值轨迹的曝光率。
在多个多模态推理基准上的实验结果表明,Shuffle-R1 在增加极少计算开销的前提下,稳定超越多种强化学习基线。这些结果验证了:以数据为中心的自适应动态算法,在提升多模态大模型强化学习效率方面极具潜力。
《FutureMind: Equipping Small Language Models with Strategic Thinking-Pattern Priors via Adaptive Knowledge Distillation》
- * 表示共同第一作者
- 论文作者:黄琨 *,徐伟恺 *,刘宇轩,王全东,高鹏至,刘伟,栾剑,王斌,安波
- 论文链接:https://arxiv.org/pdf/2505.12299
Mobile GUI Agent 引入 CoaT(Chain of Action-Planning Thoughts)虽然显著增强了推理与规划能力,但在真实落地中仍面临两大核心瓶颈:其一,高质量且多样化的 CoaT 轨迹极其稀缺,导致模型难以获得稳定、可泛化的“思考样本”;其二,现有 self-training 往往仅以最终结果作为监督信号,难以对中间推理步骤进行细粒度约束与纠偏,而引入人工过程标注或 PRM(Process Reward Model)又成本过高、难以规模化。
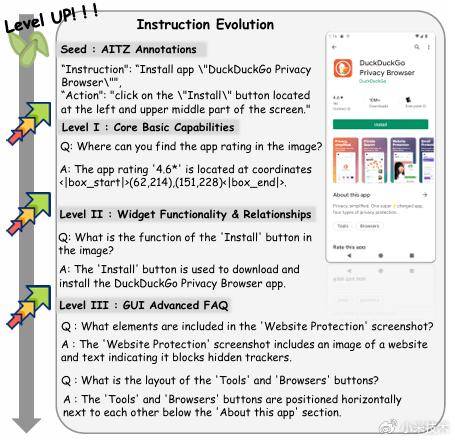
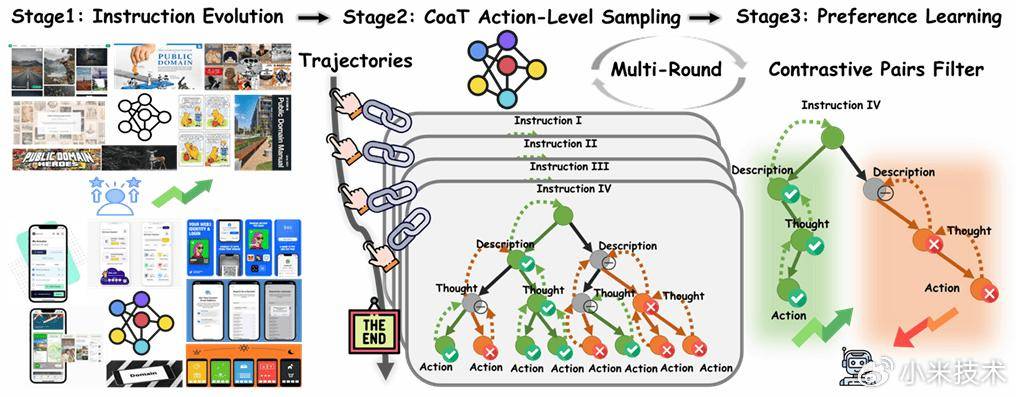
为此,我们提出 MobileIPL(Iterative Preference Learning)框架,以更高效、可扩展的方式实现过程监督:(1)Thinking-level DPO(T-DPO):通过迭代采样构建 CoaT-tree,对叶子节点进行 rule-based reward 评分,并结合反向归因将稀疏的“结果信号”精确回传至中间思考步骤,从而自动构造高质量偏好对,持续优化模型的思考过程与探索策略;(2)Instruction Evolution:引入三阶段指令演化机制(生成 + 过滤),有效扩展任务分布,显著缓解 warm-up SFT 过拟合,系统性提升 Agent 的 UI 理解能力与数据多样性。
实验表明,MobileIPL 在 AITZ、AMEX、AndroidControl 等主流 GUI-Agent 基准上取得 SOTA,并在 OOD(分布外)场景中展现出更强的泛化鲁棒性与稳定性。
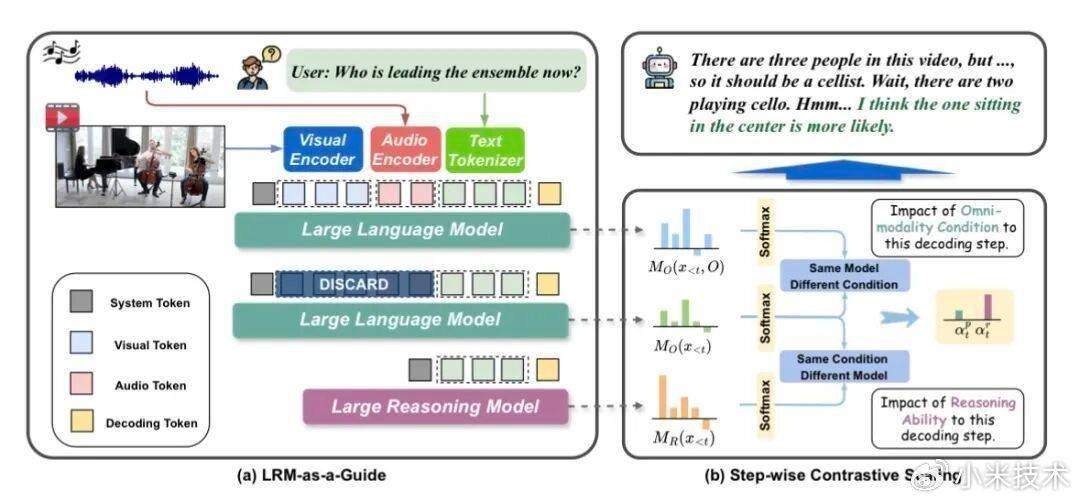
《ThinkOmni: Lifting Textual Reasoning to Omni-modal Scenarios via Guidance Decoding》
- 论文作者:杨少雄,李骏霆,张梦愿,李超,刘伟,栾剑
- 论文链接:https://openreview.net/pdf?id=gX42SSbjcC
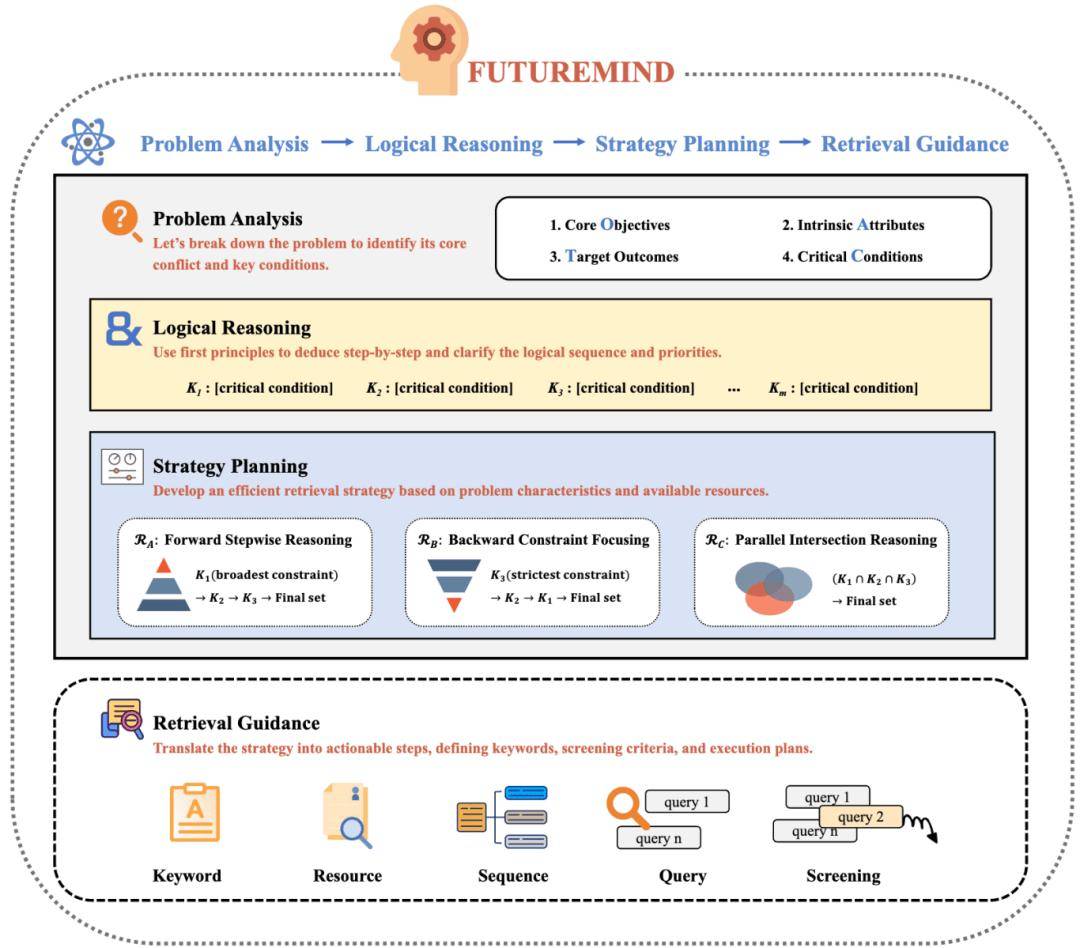
在实际业务中,小语言模型(SLMs)因其低成本、低时延优势,被广泛应用于智能问答、知识检索等场景。然而,面对多跳推理和复杂检索等高难度任务,SLMs 常因缺乏结构化推理流程与系统级检索策略而性能受限。为解决这一瓶颈,我们提出了 FutureMind,一种无需额外训练和参数增量的模块化推理框架,专注于为学生模型注入可复用的“战略性思维模式”。
FutureMind 通过自适应知识蒸馏,从大型语言模型(LLMs)中提炼出高级认知能力,包括问题分析、条件排序、策略规划及检索决策等思维先验,构建了由问题分析、逻辑推理、策略规划与检索指导模块组成的动态推理流水线。该流水线辅以三种不同的检索范式(前向、反向及并行检索策略),有效拆解复杂查询,显著减少无效调用和冗余检索,极大提升了推理效率与检索准确率。
在多跳问答基准测试上,我们进行了大量实验,结果显示 FutureMind 表现卓越,超越了如 Search-o1 等多项强基线模型。在不同模型架构和规模下,FutureMind 均在无需额外训练的前提下实现了 SOTA 水平。进一步分析发现,思维模式蒸馏仍受教师模型与学生模型认知偏差的瓶颈限制,该发现为推理能力迁移提供了全新视角,也为构建兼具高效性与真正认知能力的轻量级语言模型指明了未来方向。
《SMAN-Bench: A Cross-System Benchmark for Mobile Agents under Single- and Multi-path, Ambiguous, and Noisy Tasks》
- 论文作者:管一然,涂思凡,梁定康,朱泠皞,鞠建忠,罗振波,栾剑,刘禹良,白翔
- 论文链接:https://openreview.net/pdf?id=pMpCOjzwI1
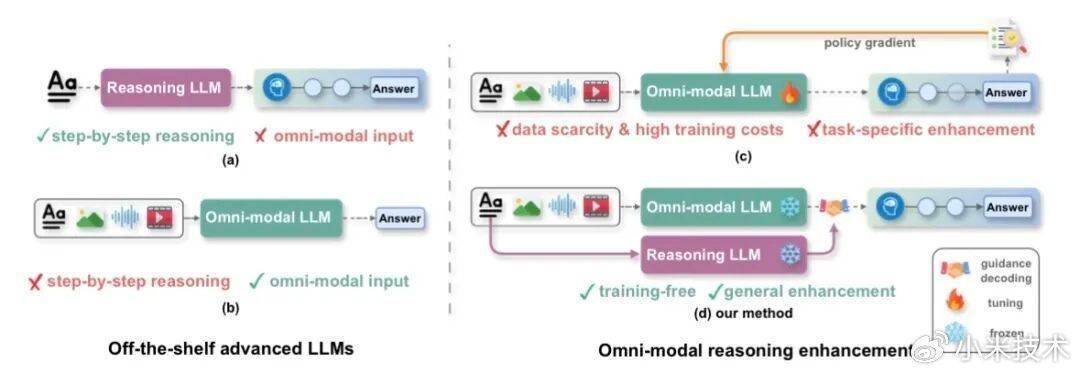
全模态推理,是智能系统从理论解题到现实应用的关键一步,但在现有技术路径中常面临两大瓶颈:一是现有的全模态大模型虽擅长感知多样化模态,却缺乏类似推理大模型的复杂逻辑推理能力,出现“感知强、推理弱”的偏科现象;二是通过额外训练来提升推理能力门槛极高,面临高质量数据稀缺、特定任务适配困难以及高昂计算成本的挑战。
为了应对上述挑战,本文提出 Training-free 的 ThinkOmni 框架,旨在将成熟的文本推理能力“零成本迁移”至全模态场景,为具备感知能力的模型外接一个“最强大脑”进行实时指导,不再依赖昂贵的模型微调和数据收集,通过策略引导实现能力的跃升。
该框架包含两大核心组件:LRM-as-a-Guide(利用现成的推理大模型来指导 OLLM 的解码过程,实现“借智推理”)、Stepwise Contrastive Scaling(自适应地平衡感知信号与推理信号),实现“感知基础与推理深度的动态平衡”。ThinkOmni 在六个多模态推理基准上均展现出一致的性能提升,为推理能力的泛化应用提供了全新思路。
《Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation》
- * 表示共同第一作者
- 论文作者:徐伟恺 *,蒋志政 *,刘宇轩,高鹏至,刘伟,栾剑,刘云新,李元春,王斌,安波
- 论文链接:https://openreview.net/pdf?id=IWDpCaSF9Q
- 项目链接:https://github.com/gezelligheid0314/Mobile-Bench-v2
- 数据连接:https://huggingface.co/datasets/xwk123/MobileBench-v2
针对现有 VLM-based 移动 Agent 评测中存在的“在线环境不稳定”与“离线轨迹过于单一”的二元对立难题,本文正式推出 SMAN-Bench —— 一个基于大规模图结构语料 Mobile3M 构建的跨系统、多维度移动 Agent 评估基准。
基于大规模图结构语料 Mobile3M ,SMAN-Bench 首创了基于槽位的指令生成方法(GIAS),不仅实现了离线环境下的多路径奖励精确评估,更通过引入真实广告噪声与交互式模糊指令,构建了高保真的移动操作模拟环境。
作为连接静态数据集与真实动态场景的桥梁,SMAN-Bench 为量化评估多模态大模型在复杂长程任务中的规划能力、抗干扰鲁棒性及主动交互智能提供了严谨且通用的实验平台。


《ReCogDrive: A Reinforced Cognitive Framework for End-to
- 论文作者:姚增伟,康魏,朱涵,郭理勇,叶凌轩,匡方军,庄伟基,李肇庆,韩志峰,林珑,Daniel Povey
- 论文链接:https://arxiv.org/pdf/2512.23278
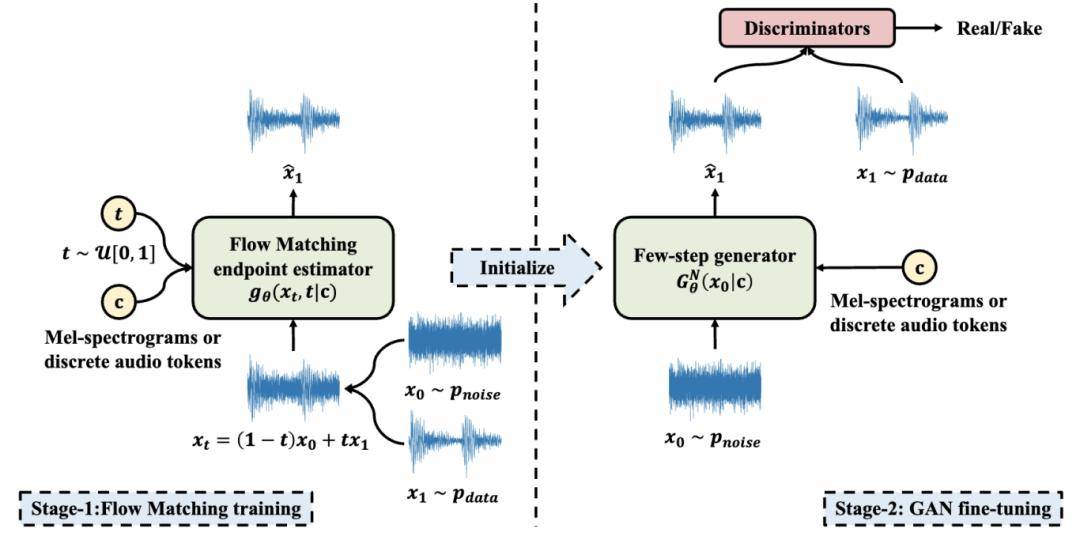
现有主流的音频生成方法主要包括生成对抗网络 (GAN) 以及基于扩散的生成方法 (如 Flow Matching)。其中,GAN 在训练过程中往往存在收敛缓慢的问题,而扩散类方法在推理阶段通常需要多步采样,带来较大的计算开销。
在本文中,我们提出 Flow2GAN,一种两阶段的音频生成框架:首先利用 Flow Matching 预训练以学习强大的生成能力,随后通过轻量 GAN 微调实现高效的少步乃至单步推理。针对音频信号的独特性质,我们对 Flow Matching 进行了专门的改进,具体包括:(1)将原始目标函数重构为端点估计 (endpoint estimation),从而避免在空能量区域进行速度场估计的优化困难;(2)引入基于谱能量的损失缩放策略,以强化对感知上更为重要的低能量 (较安静) 区域的建模。
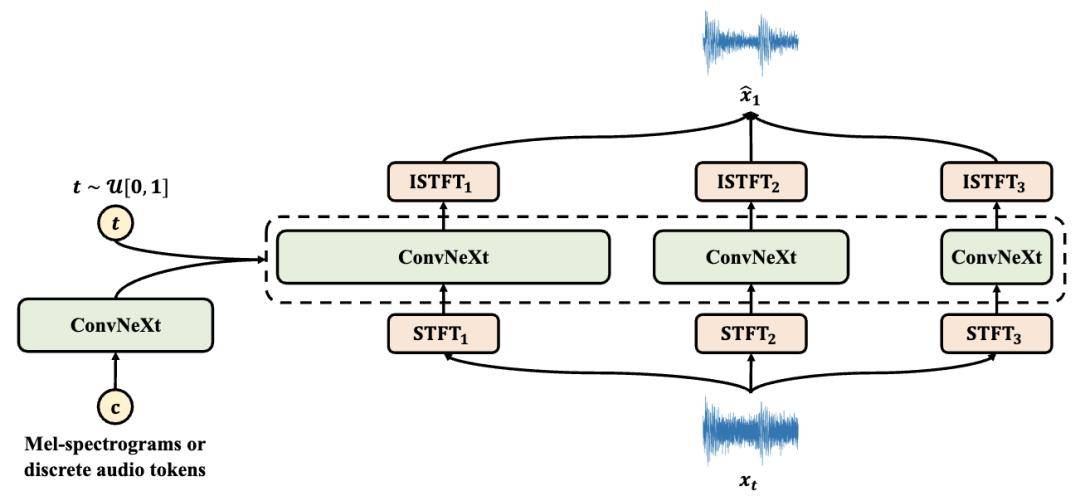
在上述 Flow Matching 改进的基础上,我们进一步引入轻量级的 GAN 微调阶段,使模型能够成为单步生成器,并在保持高效推理的同时生成高质量音频。此外,我们设计了一种多分支网络结构,在不同时间–频率分辨率下对傅里叶系数进行建模,相比以往的单分辨率设计提升了模型的音频建模能力。实验结果表明,Flow2GAN 能够从 Mel 频谱或离散音频 token 中生成高保真音频,在生成质量与计算效率的权衡上优于现有最先进的 GAN 及 Flow Matching 方法。